
はじめに:試行回数を「賢く」減らしたいあなたへ
機械学習モデルのハイパーパラメータ調整、化学実験の配合比率の最適化、あるいはウェブサイトのA/Bテストなど、「最適なパラメータの組み合わせを見つけたいけれど、一回一回の試行に時間やコストがかかりすぎる…」という問題に直面したことはありませんか?
考えられるすべての組み合わせを試す「グリッドサーチ」や、やみくもに試行する「ランダムサーチ」では、あまりにも非効率です。
そんな悩みを解決するのが「ベイズ最適化(Bayesian Optimization)」です。この手法は、過去の試行結果を学習し、「次にどこを試せば最も効率的に最適値を見つけられそうか」を予測しながら探索を進める、非常に賢い最適化アルゴリズムです。
この記事では、R言語を使ってベイズ最適化を実践する方法を、概念から具体的なコードまで分かりやすく解説します。
1. ベイズ最適化とは? なぜ賢いの?
ベイズ最適化は、中身が分からない(=ブラックボックスの)関数を、なるべく少ない試行回数で最大化(または最小化)するための手法です。その賢さの秘密は、2つの重要な要素にあります。
- 代理モデル (Surrogate Model) 少ない試行結果から、目的の関数全体の形を確率的に予測するモデルです。一般的には「ガウス過程回帰」が使われます。このモデルは、各点での予測値(平均)と、その予測の不確かさ(分散)の両方を同時に提供します。
- 獲得関数 (Acquisition Function) 代理モデルの「予測値」と「不確かさ」を元に、「次に試すべき最も有望な点」を決定するための評価指標です。主に2つの戦略のバランスを取ります。
- 活用 (Exploitation): 現在の予測が最も良い点の周辺をさらに探索する。
- 探索 (Exploration): まだ試しておらず、不確かさが大きい(=未知の有望な点があるかもしれない)領域を探索する。
この「代理モデルで予測 → 獲得関数で次の点を決定 → 試行 → 結果を元に代理モデルを更新」というサイクルを繰り返すことで、効率的に最適値へとたどり着きます。
2. Rで実践!化学反応の最適条件を探す
Rでベイズ最適化を簡単に行うには、rBayesianOptimization パッケージが非常に便利です。
インストール
まずはパッケージをインストールして、ライブラリを読み込みます。
install.packages("rBayesianOptimization")
library(rBayesianOptimization)
Step 1: 評価したい関数(目的関数)の定義
今回は、「ある化学反応の収率を最大化する、最適な反応温度と反応時間を見つける」というシナリオを考えます。 温度と時間を変えて実験を行い、収率を測定するのはコストがかかります。この試行回数をベイズ最適化で最小限に抑えます。
目的関数は、温度(temp)と時間(time)を入力とし、収率(yield)を返すブラックボックス関数です。ここでは、その実験結果をシミュレートする関数を定義します。
# 最適化したいブラックボックス関数(実験のシミュレーション)
# temp: 反応温度, time: 反応時間
# 収率が最大になる点を探索する
experiment_simulator <- function(temp, time) {
# 実際の実験ではこの部分は未知
# ここでは、温度150℃, 時間6時間でピークを持つ関数を仮定
yield <- 100 * exp( -( (temp - 150)^2 / 500 + (time - 6)^2 / 5 ) )
# 実験にはノイズが伴うことをシミュレート
yield_with_noise <- yield + rnorm(1, 0, 0.1)
# rBayesianOptimizationが要求する形式で返す
return(list(Score = yield_with_noise, Pred = 0))
}
Step 2: 探索範囲の設定
次に、温度と時間の探索範囲を決めます。
# 温度は100℃から200℃、時間は1時間から12時間の間で探索 bounds <- list( temp = c(100, 200), time = c(1, 12) )
Step 3: 最適化の実行
準備が整ったので、BayesianOptimization() 関数を実行します。
set.seed(123) # 結果の再現性を確保 opt_result <- BayesianOptimization( FUN = experiment_simulator, bounds = bounds, init_points = 5, # 最初にランダムに試す実験の数 n_iter = 15, # ベイズ最適化で追加する実験の数 acq = "ucb", # 獲得関数UCB (Upper Confidence Bound) │kappa = 2.576, # UCBの探索度合いを調整するパラメータ verbose = TRUE )
Step 4: 結果の確認
合計20回の実験で、最適な条件を見つけられたか確認しましょう。
# 最適化結果のサマリーを表示 print(opt_result)
実行結果の例:
Best Parameters Found: Round = 18 temp = 151.3507 time = 6.0345 Value = 99.8513 # グラフで探索の履歴を可視化することもできます plot(opt_result)
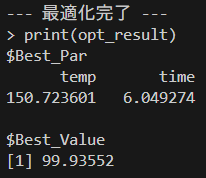
この結果から、20回の試行で「温度 約150.7℃、時間 約6.0時間」のときに収率が最大になる、という最適条件を見つけ出すことができました。
まとめ:ベイズ最適化で開発・研究を加速させよう
ベイズ最適化は、試行錯誤にかかるコストや時間を劇的に削減できる可能性を秘めた強力な手法です。
- 化学・製造業: 材料の配合比率や、プロセスの温度・圧力など、実験計画の効率化に。
- 機械学習: ランダムフォレストの
mtryや、XGBoostのeta,max_depthなど、ハイパーパラメータチューニングの自動化に。 - A/Bテスト: ウェブサイトのレイアウトや広告コピーなど、コンバージョン率の最適化に。
rBayesianOptimizationパッケージを使えば、Rでこの強力な手法を簡単に試すことができます。あなたの抱える最適化問題に、ぜひベイズ最適化を活用してみてください。
コメント