
はじめに:ただのグラフじゃもったいない!
あなたは、MatplotlibやSeabornでグラフを作成したときに、「なんだか味気ないな」「もっときれいに、分かりやすくできないかな?」と感じたことはありませんか?データ分析の結果を効果的に伝えるためには、ただグラフを作るだけでなく、その「見せ方」も非常に重要なんです。
Pythonには、基本的なグラフ作成ライブラリであるMatplotlibに加えて、より美しく、統計的なグラフを簡単に描画できる「Seaborn(シーボーン)」という強力なライブラリがあります。
この記事では、MatplotlibとSeabornを組み合わせて、より魅力的で「伝わる」グラフを作成するためのテクニックを、初心者の方にも分かりやすく解説します。あなたのデータ可視化スキルを次のレベルへと引き上げましょう!
1. MatplotlibとSeaborn:それぞれの役割
- Matplotlib: Pythonのグラフ描画ライブラリの「土台」です。グラフの要素(軸、タイトル、凡例など)を細かく制御でき、非常に柔軟性が高いのが特徴です。しかし、コードが少し複雑になりがちで、デフォルトの見た目は少し素朴です。
- Seaborn: Matplotlibをベースにして作られた、統計グラフ描画ライブラリです。より少ないコードで、統計的な情報を盛り込んだ美しいグラフを簡単に作成できます。PandasのDataFrameとの相性が抜群です。
インストール方法
どちらもPythonに最初から入っているものではないので、使う前にインストールが必要です。
pip install matplotlib seaborn
2. Seabornで「美しい」グラフを簡単に描く
散布図 (Scatter Plot):2変数の関係性を美しく
Seabornの scatterplot() は、Matplotlibの scatter() よりも少ないコードで、より洗練された散布図を描画できます。特に、カテゴリごとに色分けしたり、サイズを変えたりするのが簡単です。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'Meiryo' # 文字化け対策のため。
# サンプルデータ:架空の顧客データです
np.random.seed(42) # 乱数のシードを固定して、毎回同じ結果になるようにします
data = {
'年齢': np.random.randint(20, 60, 50),
'購入金額': np.random.randint(1000, 10000, 50) + np.random.randint(0, 5000, 50),
'性別': np.random.choice(['男性', '女性'], 50),
'満足度': np.random.randint(1, 6, 50) # 1-5の評価です
}
df = pd.DataFrame(data)
plt.figure(figsize=(8, 6))
sns.scatterplot(x='年齢', y='購入金額', hue='性別', size='満足度', data=df, sizes=(50, 500), alpha=0.7)
plt.title("年齢と購入金額の散布図(性別と満足度で色分け・サイズ変更)")
plt.xlabel("年齢")
plt.ylabel("購入金額")
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(title='凡例', bbox_to_anchor=(1.05, 1), loc='upper left') # 凡例をグラフの外に出します
plt.tight_layout() # レイアウトの自動調整です
plt.show()
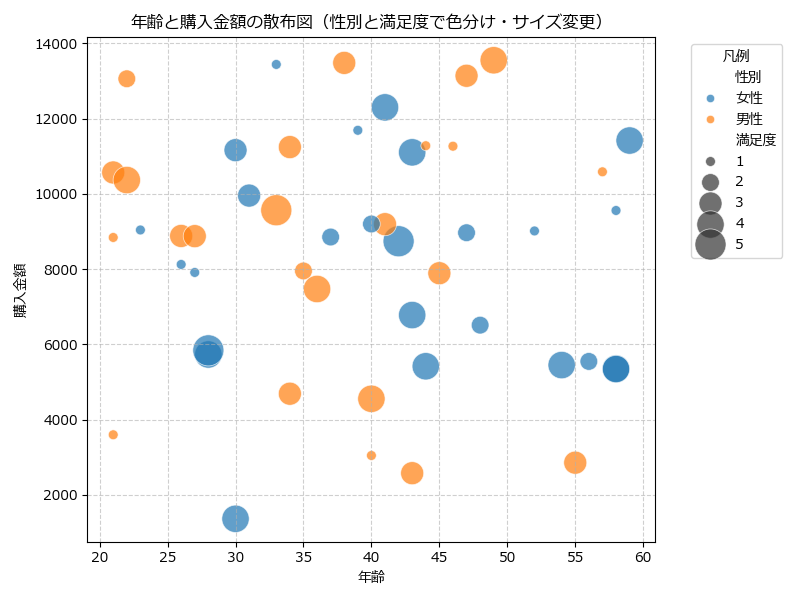
hue 引数でカテゴリごとに色分け、size 引数で数値の大小を点のサイズで表現できるのがSeabornの強みです。
棒グラフ (Bar Plot):カテゴリごとの平均値を比較
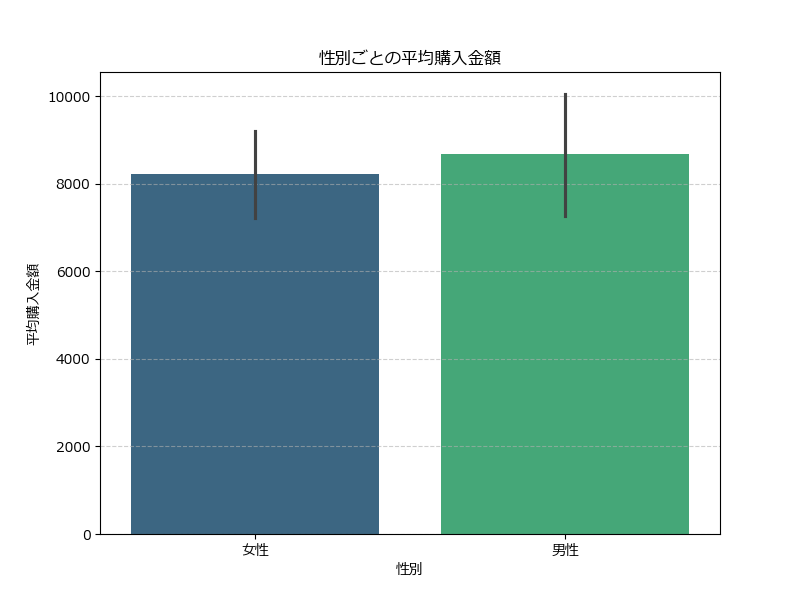
barplot() は、カテゴリごとの数値の平均値を棒グラフで表示し、信頼区間も自動で表示してくれます。
plt.figure(figsize=(8, 6))
sns.barplot(x='性別', y='購入金額', data=df, palette='viridis') # paletteで色合いを指定します
plt.title("性別ごとの平均購入金額")
plt.xlabel("性別")
plt.ylabel("平均購入金額")
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.show()
ヒストグラムとカーネル密度推定 (Distplot / Histplot):データの分布を見る
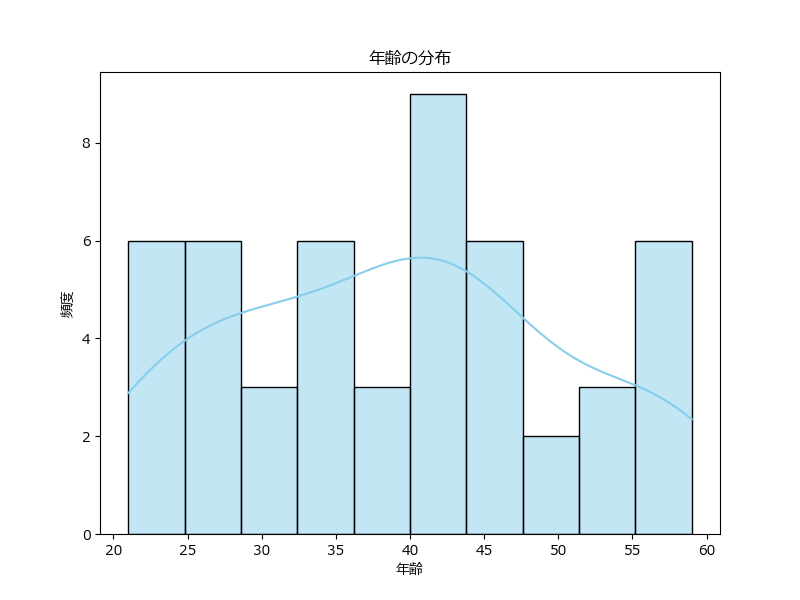
histplot() は、ヒストグラムとカーネル密度推定(KDE)を組み合わせたグラフで、データの分布をより詳細に把握できます。
plt.figure(figsize=(8, 6))
sns.histplot(df['年齢'], kde=True, bins=10, color='skyblue') # kde=TrueでKDE曲線も表示します
plt.title("年齢の分布")
plt.xlabel("年齢")
plt.ylabel("頻度")
plt.show()
箱ひげ図 (Box Plot):データのばらつきと外れ値を見る
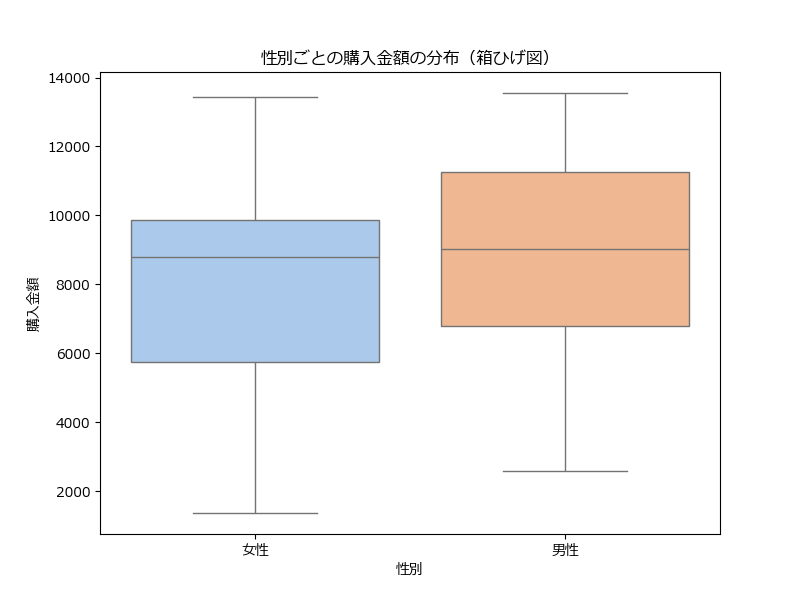
boxplot() は、データの分布、中央値、四分位数、外れ値を一目で確認できるグラフです。カテゴリごとの比較にも適しています。
plt.figure(figsize=(8, 6))
sns.boxplot(x='性別', y='購入金額', data=df, palette='pastel')
plt.title("性別ごとの購入金額の分布(箱ひげ図)")
plt.xlabel("性別")
plt.ylabel("購入金額")
plt.show()
3. MatplotlibとSeabornの連携:さらに細かくカスタマイズ
SeabornはMatplotlibをベースにしているので、Seabornで描画したグラフに対して、Matplotlibの関数を使ってさらに細かくカスタマイズすることができます。
plt.figure(figsize=(10, 7))
# Seabornで散布図を描画します
sns.scatterplot(x='年齢', y='購入金額', hue='性別', data=df, s=100, alpha=0.8)
# Matplotlibの機能で追加のカスタマイズをします
plt.title("年齢と購入金額の関係(MatplotlibとSeabornの連携)", fontsize=16, color='darkblue')
plt.xlabel("顧客の年齢", fontsize=12)
plt.ylabel("購入金額(円)", fontsize=12)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.text(20, 18000, "高額購入者層", fontsize=10, color='red') # 特定の位置にテキストを追加します
plt.annotate('注目ポイント', xy=(50, 15000), xytext=(55, 17000),
arrowprops=dict(facecolor='black', shrink=0.05),
fontsize=10, color='black') # 注釈を追加します
plt.grid(True, linestyle=':', alpha=0.7)
plt.show()
まとめ:MatplotlibとSeabornで「語る」グラフを作成しましょう!
MatplotlibとSeabornを組み合わせることで、あなたは単にデータを可視化するだけでなく、そのデータが持つストーリーを「語る」ような、美しく、そして情報量の多いグラフを作成できるようになります。
データの種類や伝えたいメッセージに応じて、適切なグラフを選択し、色やラベル、注釈などを工夫することで、あなたの分析結果はより多くの人に「伝わる」ものとなるでしょう。ぜひ、これらのライブラリを使いこなして、データ可視化の表現力を高めてくださいね!
コメント