
はじめに:データ分析、何から始めればいいの?
あなたは、Excelのような表形式のデータ(CSVファイルやデータベースのデータなど)をPythonで扱いたいと思ったことはありませんか?たくさんのデータを効率よく整理したり、特定の条件で絞り込んだり、合計を出したり…。
そんな時に絶大な威力を発揮するのが、Pythonのデータ分析ライブラリ「Pandas(パンダス)」です!Pandasは、データ分析の現場で最も広く使われているツールの一つで、複雑なデータ操作も直感的に行えるようになります。
この記事では、Pandasの基本的なデータ構造である「Series(シリーズ)」と「DataFrame(データフレーム)」の使い方を中心に、初心者の方にも分かりやすく解説していきます。データから新しい発見をする楽しさを体験しましょう!
1. Pandasって何?なぜデータ分析に必須なの?
Pandasは、数値データや時系列データ、表形式のデータを扱うための、高速で柔軟なデータ構造を提供するライブラリです。特に、Excelやデータベースのテーブルのように、行と列を持つデータを扱うのが得意なんです。
インストール方法
Pandasは標準ライブラリではないので、使う前にインストールが必要です。コマンドプロンプトやターミナルで以下のコマンドを実行してくださいね。
pip install pandas
2. Pandasの基本データ構造:SeriesとDataFrame
Series(シリーズ):1列のデータのことです
Seriesは、1次元のラベル付き配列のようなものです。Excelの1列や、データベースの1つのカラムをイメージすると分かりやすいでしょう。
import pandas as pd
# リストからSeriesを作成します
# インデックス(左側の数字)が自動で振られます
s_numbers = pd.Series([10, 20, 30, 40, 50])
print("--- Series s_numbers ---")
print(s_numbers)
# インデックスを自分で指定してSeriesを作成します
s_fruits = pd.Series([100, 150, 200], index=['りんご', 'バナナ', 'みかん'])
print("\n--- Series s_fruits(インデックス指定)---")
print(s_fruits)
# 辞書からSeriesを作成します(辞書のキーがインデックスになります)
data_dict = {'東京': 1396, '大阪': 883, '名古屋': 233} # 人口(万人)です
s_cities = pd.Series(data_dict)
print("\n--- Series s_cities(辞書から作成)---")
print(s_cities)
# 要素へのアクセスです
print(f"\nバナナの値段: {s_fruits['バナナ']}円")
print(f"東京の人口: {s_cities['東京']}万人")
# スライシング(範囲指定で要素を取り出す)です
print("\n--- りんごからみかんまでの値段 ---")
print(s_fruits['りんご':'みかん']) # インデックス名で範囲指定します
DataFrame(データフレーム):表形式のデータのことです
DataFrameは、2次元のラベル付きデータ構造で、Excelのシートやデータベースのテーブルそのものです。異なるデータ型の列を持つことができます。
DataFrameの作成方法
最も一般的なのは、辞書から作成する方法です。辞書のキーが列名になります。
# 辞書からDataFrameを作成します
data = {
'名前': ['田中', '佐藤', '鈴木', '高橋'],
'年齢': [25, 30, 35, 40],
'都市': ['東京', '大阪', '福岡', '名古屋']
}
df_people = pd.DataFrame(data)
print("--- DataFrame df_people ---")
print(df_people)
# リストのリストからDataFrameを作成します(列名を別途指定します)
data_list = [
['山田', 28, '札幌'],
['伊藤', 33, '仙台'],
['渡辺', 22, '沖縄']
]
df_more_people = pd.DataFrame(data_list, columns=['名前', '年齢', '都市'])
print("\n--- DataFrame df_more_people ---")
print(df_more_people)
3. DataFrameの基本的な操作
列(カラム)の選択
特定の列だけを取り出したい場合は、辞書のように列名を指定します。
print("\n--- '名前'列だけを選択します ---")
print(df_people['名前'])
print("\n--- '名前'と'年齢'列を選択します ---")
print(df_people[['名前', '年齢']]) # 複数列はリストで指定します
行の選択
loc:**ラベル(インデックス名や行名)**で選択します。iloc:**整数位置(0から始まる行番号)**で選択します。
print("\n--- 最初の行(インデックス0)を選択します(loc)---")
print(df_people.loc[0])
print("\n--- 2番目の行(インデックス1)を選択します(iloc)---")
print(df_people.iloc[1])
# 条件を指定して行を選択します
print("\n--- 年齢が30歳以上の人だけを選択します ---")
print(df_people[df_people['年齢'] >= 30])
新しい列(カラム)の追加
新しい列は、辞書のように列名を指定して値を代入するだけで簡単に追加できます。
df_people['既婚'] = [True, False, True, False]
print("\n--- '既婚'列を追加したDataFrame ---")
print(df_people)
列(カラム)の削除
drop() メソッドを使って不要な列を削除できます。axis=1 は「列を削除する」という意味です。inplace=True を指定すると、元のDataFrameが直接変更されます。
df_people.drop('既婚', axis=1, inplace=True)
print("\n--- '既婚'列を削除したDataFrame ---")
print(df_people)
データの読み込みと保存
Pandasは、CSV、Excel、SQLデータベースなど、様々な形式のデータを読み書きできます。
# CSVファイルを読み込む例です
# df_from_csv = pd.read_csv('your_data.csv')
# DataFrameをCSVファイルとして保存する例です
# df_people.to_csv('output_people.csv', index=False) # index=Falseでインデックスを保存しません
日経平均株価データで実践!Pandasデータ分析の具体例
ここからは、実際のデータを使ってPandasのデータ分析を体験してみましょう。今回は、日本の株式市場の代表的な指標である「日経平均株価」のデータを使います。
データの取得準備:yfinanceライブラリ
株価データを簡単に取得するために、yfinanceという便利なライブラリを使います。これは、Yahoo! Financeから株価データを取得できるツールです。
まずは、yfinanceをインストールしましょう。VS Codeのターミナルで以下のコマンドを実行してください。
pip install yfinance matplotlib
matplotlibは、グラフを描画するために必要なライブラリなので、一緒にインストールしておきましょう。
日経平均株価データの取得と確認
それでは、Pythonコードを書いて日経平均株価のデータを取得し、Pandasで扱ってみましょう。日経平均株価のティッカーシンボル(銘柄コード)は ^N225 です。
それでは、Pythonコードを書いて日経平均株価のデータを取得し、Pandasで扱ってみましょう。日経平均株価のティッカーシンボル(銘柄コード)は ^N225 です。
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
# 文字化け対策のため。
plt.rcParams['font.family'] = 'Meiryo'
# 日経平均株価のティッカーシンボル
nikkei_ticker = '^N225'
# 過去1年間のデータを取得します
# startとendで期間を指定できます
df_nikkei = yf.download(nikkei_ticker, start='2023-06-01', end='2024-06-01')
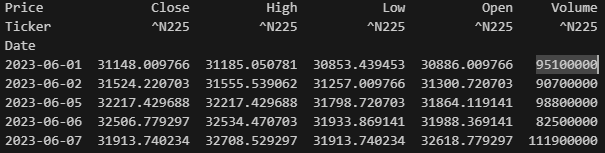
print("--- 日経平均株価データの最初の5行 ---")
print(df_nikkei.head()) # データの最初の5行を表示します
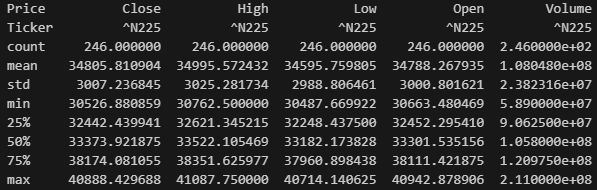
print("\n--- 日経平均株価データの基本統計量 ---")
print(df_nikkei.describe()) # データの平均、最大値、最小値などを表示します
上記のコードを実行すると、日経平均株価のデータが取得され、その一部と基本的な統計情報が表示されます。
Open: 始値High: 高値Low: 安値Close: 終値Adj Close: 調整後終値(配当などを考慮した終値)Volume: 出来高(取引量)
— 日経平均株価データの最初の5行 —
— 日経平均株価データの基本統計量 —
株価の推移をグラフで可視化しよう
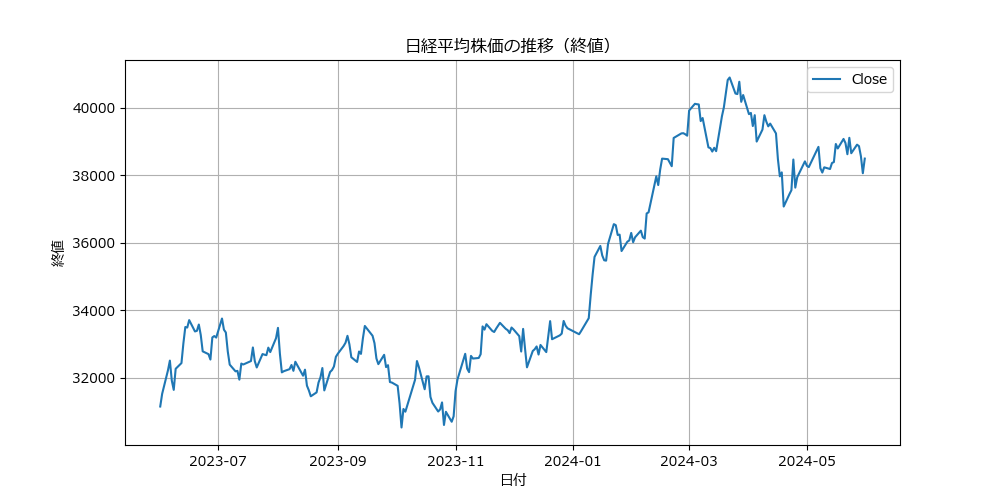
取得したデータを使って、日経平均株価の終値の推移を折れ線グラフで見てみましょう。グラフにすることで、データの傾向が視覚的に分かりやすくなります。
# 終値の推移をグラフで表示します
plt.figure(figsize=(12, 6)) # グラフのサイズを指定します
plt.plot(df_nikkei['Close'], label='日経平均株価 (終値)')
plt.title('日経平均株価の推移') # グラフのタイトル
plt.xlabel('日付') # X軸のラベル
plt.ylabel('株価 (円)') # Y軸のラベル
plt.grid(True) # グリッド線を表示します
plt.legend() # 凡例を表示します
plt.show() # グラフを表示します
このコードを実行すると、日経平均株価がどのように変動してきたかが一目でわかるグラフが表示されます。
簡単な分析例:日次リターンを計算してみよう
株価分析でよく使われる指標の一つに「日次リターン」(日々の株価の変化率)があります。これを計算してみましょう。
# 日次リターンを計算します
# (今日の終値 - 昨日の終値) / 昨日の終値
df_nikkei['Daily Return'] = df_nikkei['Close'].pct_change()
print("\n--- 日次リターンの最初の5行 ---")
print(df_nikkei.head()) # 新しい列が追加されているのがわかります
# 日次リターンのヒストグラム(分布)を見てみよう
plt.figure(figsize=(10, 5))
plt.hist(df_nikkei['Daily Return'].dropna(), bins=50, edgecolor='black') # NaN値を除外します
plt.title('日経平均株価 日次リターンの分布')
plt.xlabel('日次リターン')
plt.ylabel('頻度')
plt.grid(True)
plt.show()
pct_change()メソッドを使うと、簡単に変化率を計算できます。ヒストグラムを見ると、日次リターンがどのような範囲に分布しているか、どれくらいの頻度で大きな変動があったかなどが分かります。
まとめ:Pandasでデータ分析の扉を開きましょう!
Pandasの Series と DataFrame は、Pythonでデータ分析を行う上での強力な基盤です。データの読み込み、整形、選択、集計といった基本的な操作をマスターすることで、あなたは大量のデータから意味のある情報を引き出し、ビジネスや研究に役立てるスキルを身につけることができるでしょう。
今回は日経平均株価のデータを使って、データの取得、確認、可視化、そして簡単な分析を行いました。このように、Pandasを使えば、様々な種類のデータを手軽に分析し、そこから新しい発見をすることができます。
まずは小さなデータセットから、実際にPandasのコードを動かして、その便利さを体験してみてくださいね!
コメント