
はじめに:なぜ今、Seabornを深く学ぶべきなのか?
データ分析において「可視化」は、単に数値をグラフにする作業ではありません。それは、データに隠された物語を読み解き、複雑な関係性の中から意味のある洞察(インサイト)を掘り起こすための、強力な武器です。
PythonにはMatplotlibという優れた可視化ライブラリがありますが、「もっと少ないコードで、もっと直感的に、もっと分析に役立つグラフを作りたい」というニーズに応えるのがSeabornです。
この記事は、Seabornの基本的な使い方を知っている方を対象に、一歩進んで**「データ分析の目的を達成するために、どのグラフを、どのように使い、どう解釈すべきか」**という観点から、Seabornの機能を体系的に、そして深く掘り下げて解説します。この記事を読めば、あなたはSeabornを自在に操り、データから価値ある知見を引き出すための確かなスキルを身につけることができるでしょう。
Seabornの思想:Matplotlibとの理想的な関係
SeabornはMatplotlibを置き換えるものではなく、Matplotlibをより強力に、そして使いやすくするための高レベルなインターフェースです。
- Matplotlib(低レベルAPI): グラフの細部(軸、タイトル、凡例など)を一つ一つ手作業で組み立てるような、柔軟性が非常に高いライブラリ。
- Seaborn(高レベルAPI): 「散布図と回帰直線を描きたい」「カテゴリ別に箱ひげ図を並べたい」といった分析の「意図」を伝えるだけで、適切なグラフを自動で生成してくれるライブラリ。
基本的な作図はSeabornに任せ、最後の微調整や特殊なカスタマイズをMatplotlibで行うのが、最も効率的で強力な使い方です。
【分析目的別】Seabornプロット徹底活用術
ここからは、データ分析で遭遇するであろうシナリオ(目的)別に、最適なSeabornのプロットを紹介します。
目的1:変数の「分布」を理解する
データ分析の第一歩は、個々の変数がどのような値の広がりを持っているか(分布)を把握することです。
histplot と kdeplot:分布の形状を掴む
histplot(ヒストグラム): データをいくつかの区間(ビン)に分け、各区間のデータ数を棒グラフで表示します。分布の全体像(山、裾の広がり)を直感的に把握できます。kdeplot(カーネル密度推定): ヒストグラムを滑らかな曲線で表現したものです。複数のグループの分布を重ねて比較する際に特に有効です。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
penguins = sns.load_dataset("penguins")
# ヒストグラムとカーネル密度推定を重ねて描画
sns.histplot(data=penguins, x="flipper_length_mm", kde=True, hue="species")
plt.title("ペンギンの翼長の分布(種別)")
plt.show()
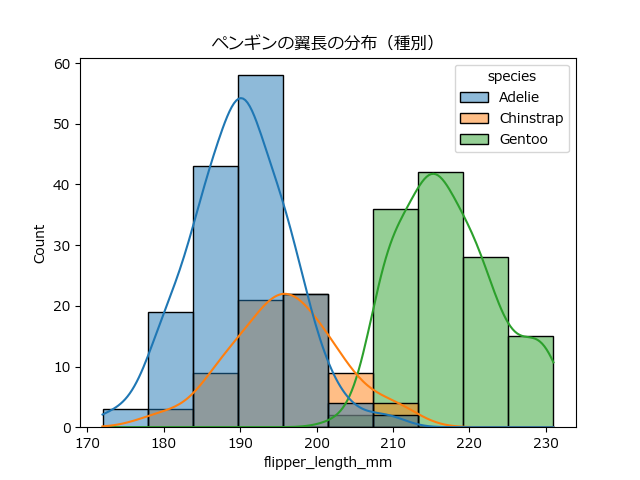
【分析のポイント】
- 山の数: 山が一つの場合(単峰性)、データが中心に集まっていることを示します。山が二つ以上ある場合(多峰性)、異なる性質を持つ複数のグループが混在している可能性があります(上記の例では種によって分布が異なることが一目瞭然です)。
- 歪み: 左右対称か、それともどちらかに裾が長く伸びているか(歪んでいるか)を見ます。
ecdfplot:累積分布でパーセンタイルを読み解く
ecdfplot(経験累積分布関数): 横軸を値、縦軸を「その値以下のデータが全体の何%を占めるか」でプロットします。中央値(50%点)や四分位数などを正確に読み取るのに便利です。
sns.ecdfplot(data=penguins, x="body_mass_g", hue="species")
plt.title("ペンギンの体重の累積分布")
plt.grid(True)
plt.show()
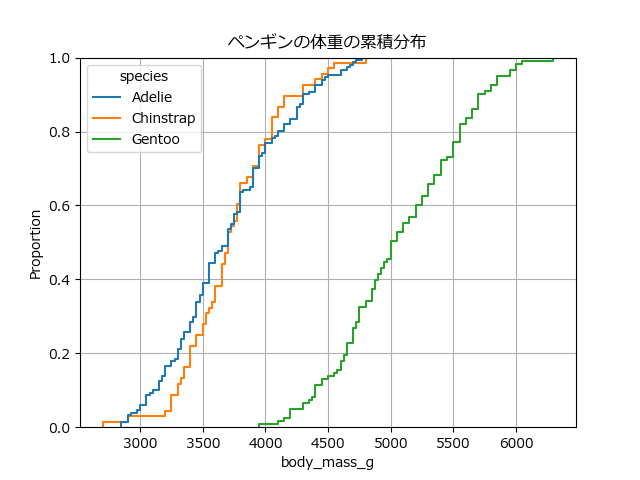
【分析のポイント】 グラフの立ち上がりが急なほど、データがその範囲に集中していることを意味します。異なるグループの曲線を比較することで、「Aグループの80%はBグループの50%の値よりも小さい」といった比較が容易になります。
目的2:変数間の「関係性」を探る
2つ以上の変数がどのように関連しているかを探るのは、データ分析の核心です。
scatterplot と regplot/lmplot:相関と回帰を見る
scatterplot(散布図): 2つの量的変数の関係を点でプロットする、最も基本的なグラフです。regplot/lmplot(回帰プロット): 散布図に加えて、データ全体の傾向を示す回帰直線と、その信頼区間(薄い色の帯)を描画します。lmplotはregplotの高機能版で、カテゴリによるグラフの分割が容易です。
# lmplotで性別ごとにグラフを分割し、回帰直線を描画
sns.lmplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="sex", col="species")
plt.suptitle("ペンギンのくちばしの長さと深さの関係", y=1.02)
plt.show()
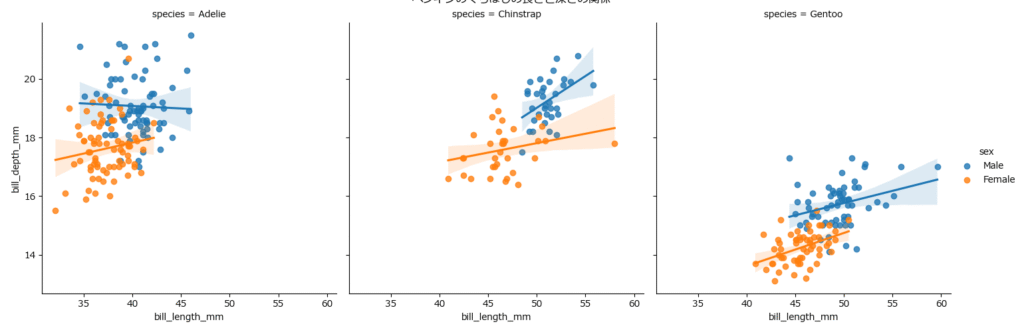
【分析のポイント】
- 点の向き: 右肩上がりなら「正の相関」、右肩下がりなら「負の相関」があると考えられます。
- 点のばらつき: 点が直線に沿って密に集まっているほど、強い相関を示します。
- 信頼区間の幅: 信頼区間が広いほど、回帰直線への当てはまりの不確実性が高いことを意味します。
jointplot と pairplot:関係性と分布を同時に把握
jointplot: 2変数の関係性(散布図や2D密度プロット)と、それぞれの変数の分布(ヒストグラムや密度プロット)を同時に表示します。pairplot: データフレームに含まれる全ての量的変数ペアに対して、総当たりの散布図(対角成分はヒストグラム)を描画します。データセット全体の概要を素早く掴むのに非常に強力です。
# データセット全体の変数ペアの関係性を一覧表示
sns.pairplot(data=penguins, hue="species")
plt.suptitle("ペンギンデータセットのペアプロット", y=1.02)
plt.show()
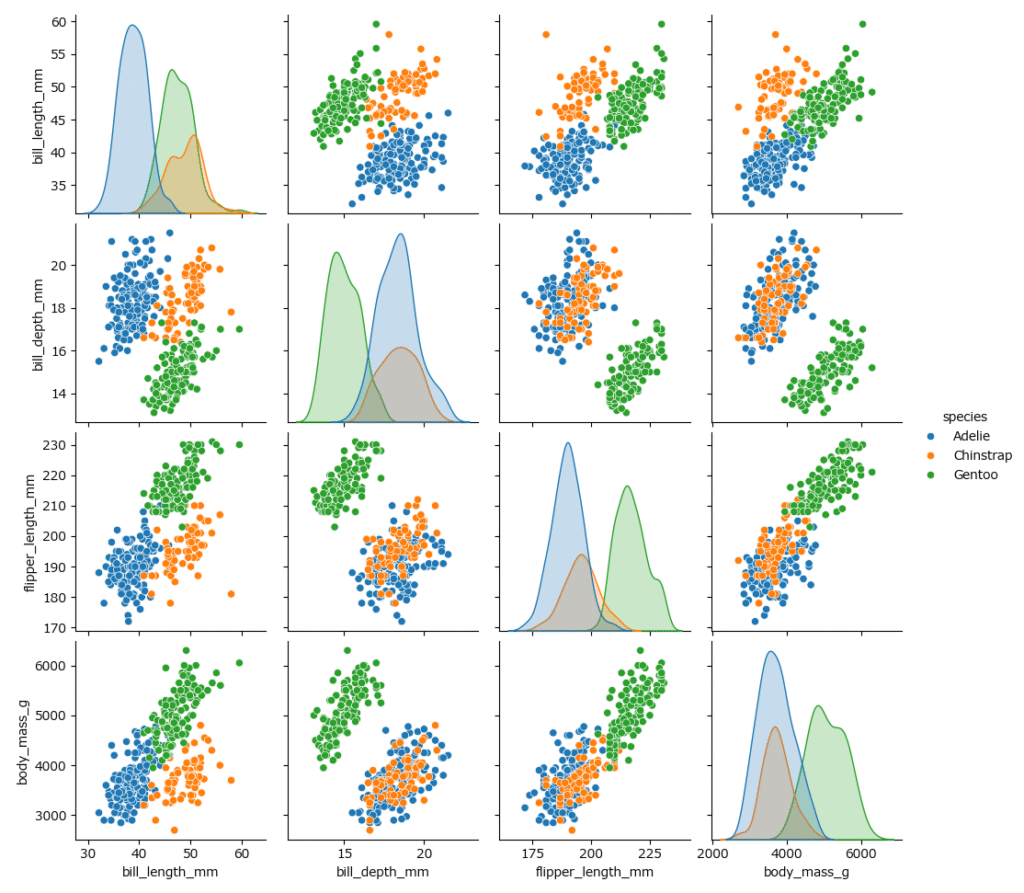
【分析のポイント】 pairplotを見ることで、どの変数間に興味深い関係がありそうか、どの変数がグループを分けるのに役立ちそうか、といった分析の当たりをつけることができます。
目的3:カテゴリによる「比較」を行う
カテゴリ(質的変数)ごとに、数値(量的変数)がどのように異なるかを比較するのも、頻出する分析タスクです。
boxplot と violinplot:分布を要約して比較する
boxplot(箱ひげ図): データの要約統計量(中央値、四分位数、外れ値)を箱とひげで表現します。複数のグループの分布のばらつきを比較するのに最適です。violinplot(バイオリンプロット): 箱ひげ図の機能に加え、カーネル密度推定によってデータの分布形状も同時に示します。箱ひげ図では分からない分布の山なども可視化できます。
plt.figure(figsize=(10, 6))
# 種と性別でグループ分けし、バイオリンプロットで翼長を比較
sns.violinplot(data=penguins, x="species", y="flipper_length_mm", hue="sex", split=True, inner="quart")
plt.title("種と性別ごとの翼長の分布")
plt.show()
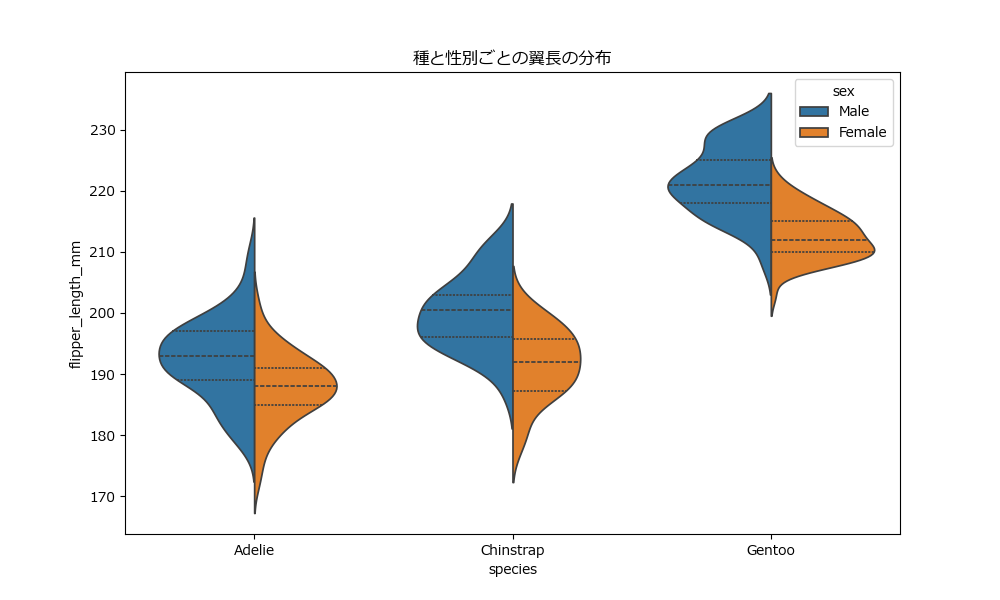
【分析のポイント】
- 箱の位置と大きさ: 箱の位置(中央値)で代表値を、箱の大きさ(四分位範囲)でデータのばらつきを比較します。
- バイオリンの形状: バイオリンの膨らんでいる部分にデータが集中しています。形状が複雑な場合、複数のグループが混在している可能性を示唆します。
barplot と pointplot:推定値を比較する
barplot(棒グラフ): カテゴリごとの数値の代表値(デフォルトは平均値)を棒の高さで示します。エラーバーは、その推定値の不確実性(信頼区間)を表します。pointplot: 棒グラフと同様の情報を、点の位置と線で表現します。複数のカテゴリ(hueで指定)にまたがる変化のパターンを比較する場合に、棒グラフよりも視覚的に理解しやすいです。
# 曜日ごとのチップの割合をポイントプロットで表示
tips = sns.load_dataset("tips")
sns.pointplot(data=tips, x="day", y="tip", hue="smoker")
plt.title("曜日と喫煙状況別のチップ額")
plt.show()
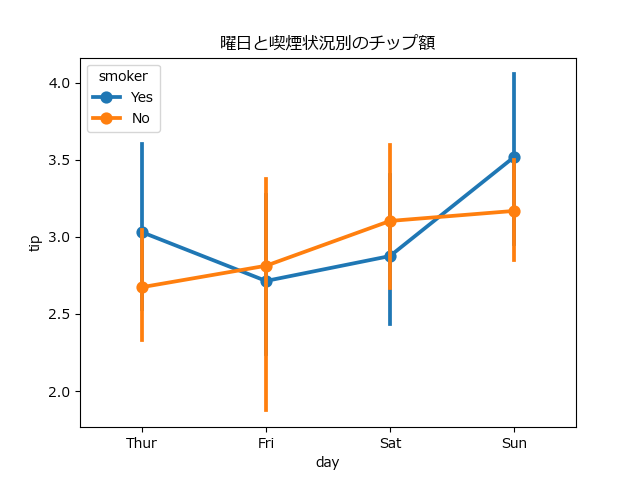
【分析のポイント】
- エラーバーの重なり: 異なるカテゴリのエラーバーが大きく重なっている場合、それらの代表値に統計的に有意な差はない可能性が高いと解釈できます。
- 線の傾き:
pointplotでは、線の傾きが急なほど、横軸のカテゴリ間での値の変化が大きいことを示します。
目的4:行列データを「パターン」として可視化する
相関行列など、2次元の行列データを可視化し、全体的なパターンを発見します。
heatmap と clustermap:行列からパターンを発見する
heatmap(ヒートマップ): 行列の各セルの値を色で表現します。相関行列を可視化し、どの変数ペアが強く相関しているかを一目で把握するのによく使われます。clustermap: ヒートマップに加えて、行と列を似たもの同士が隣り合うように並べ替える階層的クラスタリングを行います。これにより、データに潜む隠れたグループ構造やパターンが浮かび上がることがあります。
# 数値データのみ抽出し、相関行列を計算
numeric_cols = penguins.select_dtypes(include=np.number)
corr_matrix = numeric_cols.corr()
# クラスタリングを適用したヒートマップを描画
sns.clustermap(corr_matrix, annot=True, cmap="coolwarm", figsize=(8, 8))
plt.suptitle("ペンギンデータの相関行列クラスタマップ")
plt.show()
# 数値データのみ抽出し、相関行列を計算
numeric_cols = penguins.select_dtypes(include=np.number)
corr_matrix = numeric_cols.corr()
# クラスタリングを適用したヒートマップを描画
sns.clustermap(corr_matrix, annot=True, cmap="coolwarm", figsize=(8, 8))
plt.suptitle("ペンギンデータの相関行列クラスタマップ")
plt.show()
【分析のポイント】
- 色の濃淡:
heatmapでは、色が濃い(または薄い)部分に注目し、値が高い(または低い)セルの組み合わせを探します。 - デンドログラム(樹形図):
clustermapの横と上に表示される樹形図は、どの行(または列)がどのようにお互いに似ているかを示しています。近くで枝分かれしているものほど、似ていると解釈できます。
まとめ:Seabornは分析の思考を加速させる
Seabornは、単なる作図ツールではありません。データ分析のプロセス、すなわち**「問いを立て → 仮説を検証し → 新たな問いを発見する」**という思考のサイクルを強力にサポートし、加速させるためのパートナーです。
今回紹介した様々なプロットを、あなたの分析目的に合わせて自在に使い分けることで、データとの対話がより深く、実り豊かなものになるはずです。ぜひ、お手元のデータで色々なグラフを試し、Seabornの表現力の高さを実感してみてください。
コメント